TL;DR A logic vulnerability, dubbed ReBreakCaptcha, which lets you easily bypass Google’s ReCaptcha v2 anywhere on the web.
Overview
Back in 2016, I started poking around to see how hard it would be for a threat actor to find a new method that bypasses Google’s ReCaptcha v2. It would be ideal if it worked in any environment, rather than being tailored to fit a specific use case.
I would like to introduce you to ReBreakCaptcha – a brand new bypassing technique for Google’s ReCaptcha v2.
ReBreakCaptcha works in three stages:
- Audio Challenge – Getting the correct challenge type.
- Recognition – Converting the audio challenge audio and sending it to Google’s Speech Recognition API.
- Verification – Verifying the Speech Recognition result and bypassing the ReCaptcha.
As of the time of posting, it is confirmed that this vulnerability still works.
ReBreakCaptcha Stage 1: Audio Challenge
There are three types of ReCaptcha v2 challenges:
- Image Challenge – The challenge contains a description and an image which consists of 9 sub-images. The user is requested to select those sub-images that best match the given description.
- Audio Challenge – The challenge contains an audio recording, The user is requested to enter the digits that are heard.
- Text Challenge – The challenge contains a category and 5 candidate phrases. The user is requested to select those phrases which best match the given category.
ReBreakCaptcha knows how to solve ReCaptcha v2 audio challenges. Therefore, we need a methodology of how to get an audio challenge every time.
When clicking the “I’m not a robot” checkbox of ReCaptcha v2, we are often presented with the following challenge type:
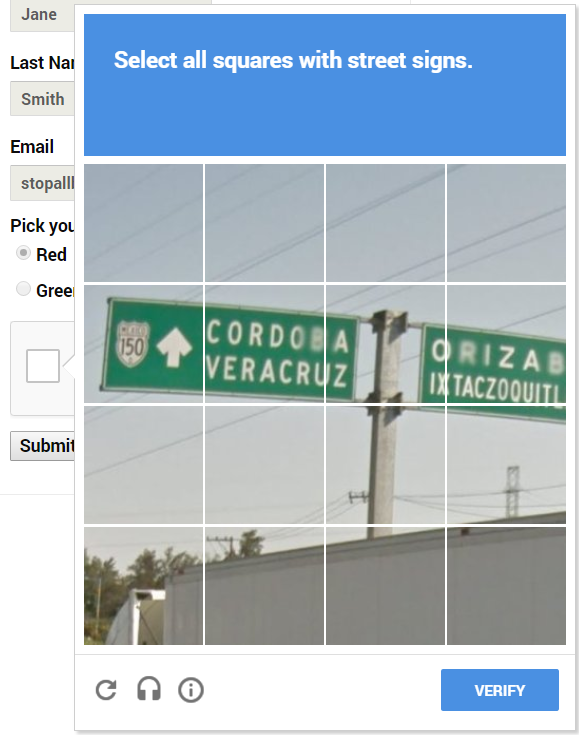
To get an audio challenge we need to click the following button:

Then we are presented with an audio challenge that can be easily bypassed:
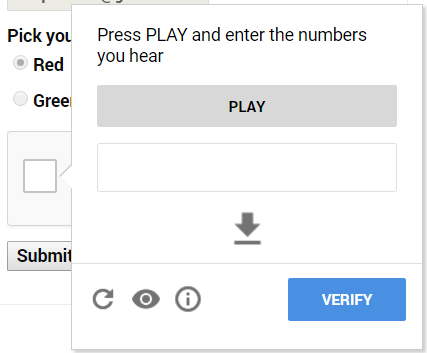
Some of you may notice that instead of an audio challenge, sometimes you get a text challenge like so:

To bypass it and get an audio challenge, you simply click the ‘Reload Challenge’ button until you get the correct type. The Reload-Challenge button:
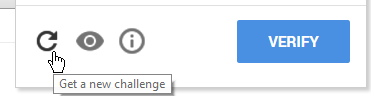
What was our goal? To bypass the ReCaptcha. Can we do this? Yes. How? Google Speech Recognition API!
ReBreakCaptcha Stage 2: Recognition
Now comes the fun part, taking advantage of one Google’s service to beat another Google’s service!
Let’s get back to the audio challenge (Figure 3).
As you can see, the controls on this challenge page are:
1. A play button – to hear the challenge.
2. A textbox – for user input.
3. A download button – to download the audio challenge.
Let’s download the audio file and send it to Google Speech Recognition API. Before doing so, we will convert it to a ‘wav’ format which is requested by Google’s Speech Recognition API.
Now we have the audio challenge file and are ready to send it to Google Speech Recognition.
How can this be done? Using their API.
There is a great Python library named SpeechRecognition for performing speech recognition, with support for several engines and APIs, online and offline.
We will use this library implementation of Google Speech Recognition API.
We will send the ‘wav’ audio file and the Speech Recognition will send us back the result in a string (e.g. ‘25143’).
This result will be the solution to our audio challenge.
ReBreakCaptcha Stage 3: Verification
This stage is fairly short. All we need to do now is to copy-paste the output string from Stage 2 into the textbox, and click ‘Verify’ on the ReCaptcha widget.
That’s right, we now semi-automatically used Google’s Services to bypass another service of its own.
ReBreakCaptcha Complete Proof-Of-Concept
I have proceeded and made a complete POC script using Python.
It utilizes all of the presented stages of the technique for a fully-automated bypass of ReCaptcha v2.
Link to the GitHub repository: https://github.com/eastee/rebreakcaptcha
3/2/2017- Update:
It has come to my attention that a lot of people encounter a harder version of the audio challenge. Therefore, I have commited a workaround to the GiHub Repo that should overcome this situation, though at a lower success rate compared to the original easier audio challenges.
It is still not fully clear how this harder version is triggered, but the number one reason suspected is when your IP is suspicious to Google.
This is usually the case when one uses a public proxy / VPN, as their IP’s are flagged in the Google system as suspicious (harder ReCaptcha’s and more ReCaptcha encounters).
3/3/2017 – Update #2:
It seems that Google has fully patched this: raising the minimum number of digits from 4-5 to 10-12 and introducing new digit recordings that are harder to speech recognize, as well as background noise. The POC has stopped working as a result. It’s been fun while it lasted 🙂

Hi, to start thanks for your research about this. I’ve testing in 3 examples, and none had the correct answer: first one only detected 3 out of 6 numbers, the seconds had 10 digits, one of them wrong, and the third couldn’t recognise.
Also, it seams that google implement a max number of retries for audio challenge.
LikeLike
Hello David,
Thank you for reading my post.
It seems that your IP was suspicious to Google, thus you got a much harder than normal version of the audio challenge (the easy ones are 4-5 in length).
First, please update your code from the GitHub Repo, as I commited a workaround for this problem (though success rate is lower than the easier ones).
Then, may I ask you to try changing your IP / not use any proxy nor VPN (VPN IP’s are known to be more suspicious- thus harder challenges, more captchas than normal etc.)
LikeLike
Well done, I wrote this exact script over a year ago and now your burned it. For what… 15 mins of fame?
LikeLike
Automate your Google NoCaptcha (I’m not a robot) captchas at a rate of $2.8 per 1000 solves. See https://www.captchasolutions.com/nocaptcha/
LikeLike
use https://www.9kw.eu/register_162976.html Captcha automatic, Cost $0
Better then captchasolutions.com
LikeLike
The hard part is writing a script that can jump through the many random extra hurdles that are required, and completely automating it without any user intervention and solving it in a reasonable amount of time.
First thing I encountered in this approach:
“Multiple correct solutions required – please solve more.”
Great that you’ve coded this case in, but the audio is sufficiently garbled enough that over 10 tries, it still hasn’t solved it.
[1] Clicking on audio challenge
[1] Google Speech Recognition: cl350 6178
[1] Need to solve more. Let’s do this!
[1] Google Speech Recognition: 3156 7711
[1] Need to solve more. Let’s do this!
[1] Google Speech Recognition: 297 bh2433
[1] Need to solve more. Let’s do this!
[1] Google Speech Recognition: nice ring to 129 route 27
[1] Need to solve more. Let’s do this!
[1] Google Speech Recognition could not understand audio
[1] Need to solve more. Let’s do this!
[1] Google Speech Recognition could not understand audio
[1] Need to solve more. Let’s do this!
[1] Google Speech Recognition could not understand audio
[1] Need to solve more. Let’s do this!
[1] Google Speech Recognition could not understand audio
[1] Need to solve more. Let’s do this!
[1] Google Speech Recognition could not understand audio
[1] Need to solve more. Let’s do this!
Eventually the code broke.
CouldntDecodeError(“Decoding failed. ffmpeg returned error code: {0}\n\nOutput from ffmpeg/avlib:\n\n{1}”.format(p.returncode, p_err))
pydub.exceptions.CouldntDecodeError: Decoding failed. ffmpeg returned error code: 1
[mp3 @ 0000000000706e40] Failed to read frame size: Could not seek to 1154.
c:\users\dave\appdata\local\temp\tmpaelusk: Invalid argument
So, this is not a working solution.
LikeLike
Hello Dave,
Thank you for reading my post.
It seems that your IP was suspicious to Google, thus you got a much harder than normal version of the audio challenge (the easy ones are 4-5 in length).
First, please update your code from the GitHub Repo, as I commited a workaround for this problem (though success rate is lower than the easier ones).
Then, may I ask you to try changing your IP / not use any proxy nor VPN (VPN IP’s are known to be more suspicious- thus harder challenges, more captchas than normal etc.)
As for the traceback- it should be an issue in the GitHub Repo, not here.
I can add a catch for that exception but it seems to be low memory issue / unfinished audio download.
LikeLike
Thanks for your reply. Unfortunately your script still does not work and stops after multiple tries and these errors:.
best_hypothesis = max(actual_result[“alternative”], key=lambda alternative: alternative[“confidence”])
KeyError: ‘confidence’
and
audio_output = self.string_to_digits(recognizer.recognize_houndify(audio, client_id=HOUNDIFY_CLIENT_ID, client_key=HOUNDIFY_CLIENT_KEY))
File “C:\Python27\lib\site-packages\speech_recognition\__init__.py”, line 960, in recognize_houndify
base64.urlsafe_b64decode(client_key),
File “C:\Python27\lib\base64.py”, line 119, in urlsafe_b64decode
return b64decode(s.translate(_urlsafe_decode_translation))
File “C:\Python27\lib\base64.py”, line 78, in b64decode
raise TypeError(msg)
TypeError: Incorrect padding
I’m using my home IP, and it should not be ‘suspicious’ to google at all. The script is not guessing the numbers correctly, in fact some of the guesses even have words in them not numbers.
Are you saying this only works on ‘easy’ short length captchas with a low rate of success, in my case 0% success rate, and after multiple tries, and after a few minutes. I’m wondering if you can provide a video of it solving correctly for 10 captchas in a row. That would be enough to prove that it is an ‘easy bypass’. As it stands, this is not a feasible solution, it didn’t solve the captcha even once.
LikeLike
It was already prooved in 2012:
https://arstechnica.com/security/2012/05/google-recaptcha-brought-to-its-knees/
But, it is not exploitable – when Google identified high volvume attacks, the voice captcha is changed into a more complex voice which cannot be identified via this tool.
A Proof of Concept was already created by AppSec Labs, in Sep 2016:
LikeLike
Hello AppSec 🙂
This is the first time it comes to my attention that something like this has already been around for so long, though is quite different from this blog post (audio analysis using own taught neural networks vs. years of experience speech recognition services that are self improving using users data).
2012.. 5 years later and we’re back to square one, although this is a complete new product (ReCaptcha V2 + some more revisions).
First, please see the updated code of the GitHub Repo, as I commited a workaround for the complex audio problem (though success rate is lower than the easier audios).
Second, your POC is nice but is manual and takes a long time to complete- thus rendering it non useful in a bot scenario.
My POC is fully automatic- without human interaction at all- thus breaks the ReCaptcha most important intention- to block non human site interaction.
LikeLiked by 1 person
The attack is not expliutable. When google identifies high-level attacks, the voice captchas are unrecongnizable for speech recognition.
LikeLike
Awesome post, btw how does Pingback work on your blog?
LikeLike
Hello Nikita,
Thank you for reading my post.
There are many Pingbacks to this blog post, so I’d say it works as expected.
If you encounter any problem, try asking for help in the official WordPress forums.
LikeLike
According to google:
“This mechanism is working as intended. The more difficult audio patterns are only triggered only when abuse/non-human interaction is suspected”.
http://www.debasish.in/2014/04/attacking-audio-recaptcha-using-googles.html
LikeLike
Hi, i work on this captcha audio too, but only i didn’t use google speechAPI, i use another method,
i use nuance dragon naturally speaking for recognizing the audio and i think this software run good for that although this software not 100% can give exact number but it can help to type the number (have to reload the audio when the number only appear 2 digits) . and i had another challenge because i want to run this method automatically, if you could help then? (maybe some script in imacros+java)
thank you in advance
LikeLike
I am so sick of lame captchas. thank you for your hard work. you are all villains. Why is there not a better solution for keeping spam out?
LikeLike
Recaptcha solving with 2captcha method – 100% working
LikeLike